Pandas包含多個內置函數,如sum、mean、max、min等,我們可以應用到 DataFrame 或分組數據中。他可以提高你在數據處理和分析方面的效率。而在這邊加權平均數是一個很好的使用例子,因為它是一個容易理解但有用的公式。我發現,在查看某些數據集合時,它比簡單的平均數更直觀。在pandas中建立一個加權平均函數是比較簡單的,但是當與其他 pandas 函數(groupby) 結合起來時,會起到不可思議的作用。本文將討論為什麼你會選擇使用加權平均數來觀察你的數據的基本原理,然後介紹如何在pandas中構建和使用這個函數。本文所展示的基本原則將有助於在pandas中建立更複雜的分析,也應該有助於理解如何在pandas中處理分組數據。
加權平均數是一個常見的操作方式,在 Excel 中實現這項功能也非常容易,在上一章節我們說明了簡單數據分類,然而在本章中我將要更近一步的使用數據分組的功能,利用 Groupby 完成分組,以及多重聚合,達成數據分組來進行加權平均法,開始前我們要延續上一篇我們所自訂的 wavg 函數,這項函數將統計方法能夠使我們達成分組加權更加容易 。
def wavg(group, avg_name, weight_name):
d = group[avg_name]
w = group[weight_name]
try:
return (d * w).sum() / w.sum()
except ZeroDivisionError:
return d.mean()
通常 groupby常用於總結數據。例如,如果我們想看一下經理的Current_Price的平均值,用groupby就很簡單,我們可以 .apply() 的方式快速應用函數 wavg,我們可以快速選定後面要利用什麼(Current_Price 搭配 Quantity)或是(New_Product_Price 搭配 Quantity)。
sales.groupby("Manager").apply(wavg, "Current_Price", "Quantity")
sales.groupby("Manager").apply(wavg, "New_Product_Price", "Quantity")

或者是直接分類 Manager 和 State,並且同樣應用上這個函數,他根據了不同的 Manager 名稱並且做 State 分類,來更細項的計算 New_Product_Price 與 Quantity 之間的加權關係。
sales.groupby(["Manager", "State"]).apply(wavg, "New_Product_Price", "Quantity")
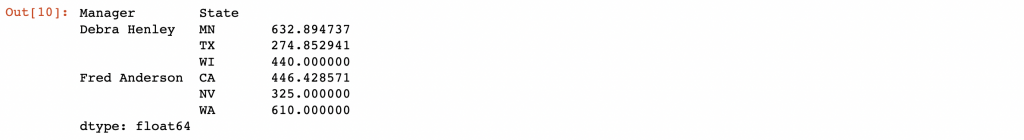
我想介紹的最後一個項目是對數據進行多重聚合(multiple aggregation)能力。例如說如果我們想得到一些列的平均值,一個列的中位數和另一個列的總和,我們可以通過定義一個帶有列名和要調用的聚合函數的字典來實現。然後,我們在分組的數據上調用 agg() 函數。
這項方式讓我們在做 Groupby 分組時可以同時完成聚合統計目標,我們使用 groupby("Manager") 完成主管名稱分類,並且按照需求利用 New_Product_Price 求得平均數 mean, 而 Current_Price 則求得中位數 median, 最後則在 Quantity 同時設定了 ['sum', 'mean']。
f = {'New_Product_Price': ['mean'],
'Current_Price': ['median'],
'Quantity': ['sum', 'mean']}
sales.groupby("Manager").agg(f)

今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。

